Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Само это понятие было введено в математику Фрэнсисом Гальтоном в 1886 году. Регрессия бывает:
Пример 1
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
Число 64,1428 показывает, каким будет значение Y, если все переменные xi в рассматриваемой нами модели обнулятся. Иными словами можно утверждать, что на значение анализируемого параметра оказывают влияние и другие факторы, не описанные в конкретной модели.
Множественная регрессия
y=f(x1+x2+…xm) + ε, где y — это результативный признак (зависимая переменная), а x1, x2, …xm — это признаки-факторы (независимые переменные).
Для множественной регрессии (МР) ее осуществляют, используя метод наименьших квадратов (МНК). Для линейных уравнений вида Y = a + b1×1 +…+bmxm+ ε строим систему нормальных уравнений (см. ниже)
Чтобы понять принцип метода, рассмотрим двухфакторный случай. Тогда имеем ситуацию, описываемую формулой
Отсюда получаем:
где σ — это дисперсия соответствующего признака, отраженного в индексе.
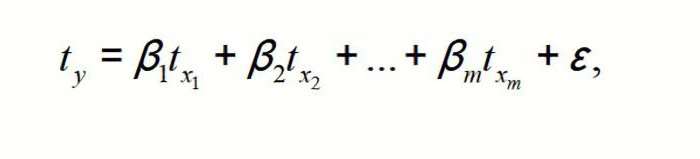
Обратите внимание, что все βiв данном случае заданы, как нормируемые и централизируемые, поэтому их сравнение между собой считается корректным и допустимым. Кроме того, принято осуществлять отсев факторов, отбрасывая те из них, у которых наименьшие значения βi.
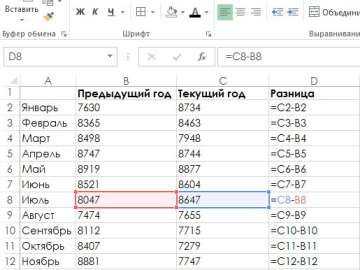
Предположим, имеется таблица динамики цены конкретного товара N в течение последних 8 месяцев. Необходимо принять решение о целесообразности приобретения его партии по цене 1850 руб./т.
Строим по ним линейное уравнение вида y=ax+b, где в качестве параметров a и b выступают коэффициенты строки с наименованием номера месяца и коэффициенты и строки «Y-пересечение» из листа с результатами регрессионного анализа. Таким образом, линейное уравнение регрессии (УР) для задачи 3 записывается в виде:
или в алгебраических обозначениях
Анализ результатов
КМК R дает возможность оценить тесноту вероятностной связи между независимой и зависимой переменными. Ее высокое значение свидетельствует о достаточно сильной связи между переменными «Номер месяца» и «Цена товара N в рублях за 1 тонну». Однако, характер этой связи остается неизвестным.
F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Задача о целесообразности покупки пакета акций
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид:
Далее:
Отмечают пункт «Новый рабочий лист» и нажимают «Ok».
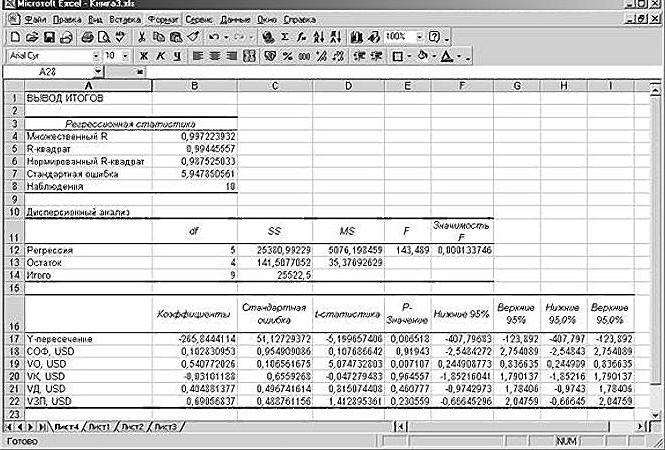
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
В более привычном математическом виде его можно записать, как:
Данные для АО «MMM» представлены в таблице:
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.