Использование поддержки XML
Узнайте, как использовать поддержку XML в PHP для чтения данных, выгруженных из Microsoft® Excel® 2003 в XML-формате, и как экспортировать данные в XML-формате из PHP-приложений для использования в электронных таблицах Excel.
Пакет Microsoft Office 2003 для операционной системы Microsoft Windows® открыл для разработчиков целый ряд новых возможностей, с которыми они не сталкивались прежде. Конечно, в вашем распоряжении имелся набор новых функций, однако наиболее значимым преимуществом стало добавление поддержки файловых XML-форматов. В Office 2003 вы можете сохранить электронную таблицу Microsoft Excel в XML-формате и использовать ХМL-файл так же, как и его двоичный эквивалент. То же самое касается и Microsoft Word.
Почему же XML-формат имеет такое большое значение? Потому, что на протяжении многих лет истинная мощь Excel или Word была заблокирована использованием файлов в двоичных форматах, а доступ к этим файлам извне можно было получить только с помощью программ-конвертеров. Теперь же файлы Excel или Word можно читать и записывать с помощью таких инструментов, как XSLT (Extensible Stylesheet Language Transformation) или DOM (XML Document Object Model), встроенных в язык программирования PHP.
В этой статье я покажу, как написать Web-приложение на PHP, которое использует эти форматы для чтения данных из электронной таблицы Excel и записи их в БД, а также для экспорта содержимого таблицы БД в электронную таблицу Excel.
Создание базы данных
В этой статье приведен пример простого Web-приложения, которое наглядно покажет вам работу XML-механизма Excel. Это приложение представляет собой таблицу, содержащую имена людей и их адреса электронной почты.
Синтаксис для создания схемы базы данных в MySQL выглядит следующим образом.
Листинг 1. SQL-код для создания схемы базы данных
Этот файл является простой базой данных, состоящей из одной таблицы с именем names, которая имеет пять полей: автоинкрементный идентификатор, имя, отчество, фамилия и адрес электронной почты.
Создайте базу данных с помощью инструмента командной строки Mysqladmin: mysqladmin —user=root create names. Затем загрузите в нее данные о таблице из файла схемы: mysql —user=root names < schema.sql. Используемые имя пользователя и пароль зависят от настроек вашего экземпляра MySQL, но сама идея не меняется — сначала создается база данных, а затем с помощью SQL-файла создаются таблицы с необходимыми полями.
Получение данных для импорта
Теперь нужно получить данные, которые будут импортироваться. Для этого создайте новый файл Excel. В верхней ячейке каждого столбца введите значения First, Middle, Last и Email. После этого добавьте в список несколько строк данных (рисунок 1).
Рисунок 1. Данные для импорта
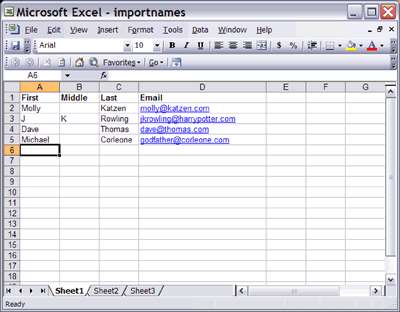
Вы можете создать список любой длины или изменить поля так, как сочтете нужным. PHP-сценарий импортирования, рассматриваемый в этой статье, безоговорочно игнорирует первую строку данных, считая ее строкой заголовков. В рабочем приложении, вы можете считывать и выполнять разбор строки заголовков, чтобы определять, какие поля содержатся в столбцах, и вносить соответствующие изменения в логику импорта.
Последний шаг — это сохранение файла в формате XML. Для этого щелкните пункт меню File > Save As и в диалоговом окне Save As выберите формат XML Spreadsheet из раскрывающегося списка Save as type (рисунок 2).
Рисунок 2. Сохранение файла в виде электронной таблицы XML

После создания XML-файла можно приступать к написанию PHP-приложения.
Импорт данных
Импорт данных начинается с создания несложной страницы, на которой выбирается входной XML-файл Excel (рисунок 3).
Рисунок 3. Выбор входного XML-файла Excel

Код этой страницы показан в листинге 2.
Листинг 2. Код страницы загрузки
Я присвоил файлу расширение .php, хотя на самом деле это вовсе не PHP. Это обычный HTML-файл, позволяющий пользователю указать файл и передать его на страницу import.php, на которой начинается все самое интересное.
Чтение XML-данных Excel
Для простоты я разделил написание страницы import.php на два этапа. На первом этапе выполняется разбор XML-данных и их вывод в форме таблицы. На втором этапе добавляется логика, в которой реализовано добавление записей в базу данных.
В листинге 3 показан пример XML-файла Excel 2003.
Листинг 3. Пример XML-файла Excel
Я вырезал часть строк из середины листинга, иначе здесь было бы напечатано все содержимое файла Excel. Листинг 3 является сравнительно чистым кодом XML. Обратите внимание на то, что в разделе заголовков в начале листинга содержится информация о документе и его авторе, задаются определенные правила отображения, стили списков и так далее. Затем в виде набора рабочих листов внутри главного объекта Workbook представлены непосредственно сами данные.
Первый объект Worksheet содержит реальные данные. Данные в этом объекте располагаются внутри тега Table, который в свою очередь содержит набор тегов Row и Cell. В каждом теге Cell располагается связанный с ним тег Data, содержащий данные ячейки. В нашем примере данные всегда представлены в виде строк (тип String).
По умолчанию при создании нового документа Excel создаются три рабочих листа с именами Sheet1, Sheet2 и Sheet3. Я не стал удалять второй и третий лист, поэтому в конце листинга вы можете видеть эти пустые листы.
В листинге 4 показана первая версия сценария import.php.
Листинг 4. Первая версия сценария импорта
Сценарий начинается с чтения временного файла, загруженного в объект DOMDocument. Затем выполняется поиск всех тегов Row. Первая строка пропускается в соответствии с логикой обработки переменной $first_row. Далее для каждой строки выполняется циклический анализ каждого содержащегося в ней тега Cell.
Следующая хитрость заключается в определении столбца, в котором вы находитесь. Как видно из листинга 3, в теге Cell не указан номер строки или столбца — за этим должен следить сценарий. На самом деле все еще немного сложнее. В действительности в теге Cell содержится атрибут ss:Index, указывающий, в каком столбце находится ячейка, если в текущей строке присутствуют пустые столбцы. Это именно то, что ищет код функции getAttribute(’index’).
После определения индекса не остается ничего сложного. Значение ячейки помещается в локальный элемент, связанный с этим полем. Затем в конце строки вызывается функция add_person для добавления данных о человеке в результирующий набор
В самом конце с помощью обычных функций PHP найденные данные выводятся в виде HTML-таблицы (рисунок 4).
Рисунок 4. Вывод данных в виде HTML-таблицы

Следующим шагом нужно загрузить информацию в базу данных.
Добавление информации в базу данных
После добавления полученного содержимого строки в структуру PHP необходимо занести его в базу данных. Для этого я добавил код, использующий модуль Pear DB (листинг 5).
Листинг 5. Вторая версия сценария импорта
На рисунке 5 показан вывод данных в браузере Firefox.
Рисунок 5. База данных
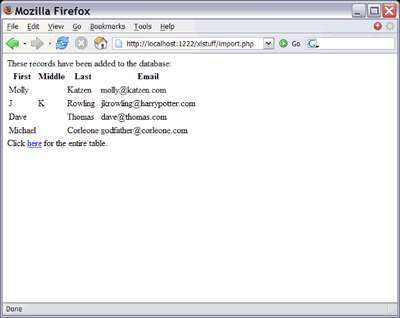
Результат выглядит не очень красиво, но это не важно. Важно то, что с помощью операторов prepare и execute можно добавить информацию в базу данных. Чтобы показать это, я создал еще одну страницу под названием list.php, отображающую информацию, полученную из базы данных (листинг 6).
Листинг 6. List.php
Эта простая страница начинается с применения SQL-функции select к таблице names. После этого создается таблица, в которую с помощью метода fetchInto добавляются все строки.
На рисунке 6 показаны данные, отображаемые этой страницей.
Рисунок 6. Данные на странице list.php
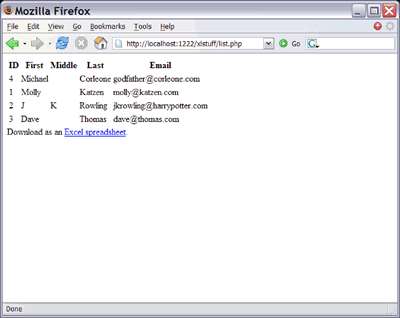
Несмотря на не очень красивый вид страницы, общая идея занесения информации в базу данных должна быть понятна. Это, в свою очередь, послужит основой сценария, генерирующего XML-файл для экспорта в Excel.
Создание XML-файла для экспорта в Excel
Заключительным шагом является создание XML-файла Excel. Я начал с того, что скопировал XML-содержимое Excel в PHP-сценарий (листинг 7), поскольку это простейший способ получить XML-файл Excel, который будет корректно проанализирован (поскольку Excel очень требователен к своему XML-формату).
Листинг 7. Страница экспорта XML
Сценарий начинается с того, что для результирующего вывода устанавливается формат XML. Это важно, поскольку в противном случае браузеры будут воспринимать этот код просто как некорректный HTML.
Я изменил часть кода, содержащую SQL-запрос, таким образом, чтобы результаты запроса сохранялись в массив. В данном случае необходимо поместить в атрибут ss:ExpandedRowCount количество строк плюс одну строку (отвечающую за заголовки). Если бы это была обычная страница отчета, дополнительная строка заголовков была бы не нужна.
На рисунке 7 показан результат открытия страницы в браузере.
Рисунок 7. Полученное XML-содержимое в браузере Firefox

Не очень впечатляет. Но посмотрите, что произойдет, когда я открою эту же ссылку в Internet Explorer (рисунок 8).
Рисунок 8. Полученное XML-содержимое в браузере Internet Explorer
Почувствуйте разницу. Теперь это полноценная электронная таблица с форматированием, открытая в браузере (конечно, в Firefox вы можете щелкнуть правой кнопкой мыши на ссылке, сохранить XML-код в файле и, таким образом, открыть его).